

1. Medidas de Variabilidade
Segundo o dicionário online Britannica (2023), medidas de variabilidade são medidas estatísticas que são usadas para descrever a propagação ou dispersão de dados. Elas são comumente usadas na análise de dados geográficos para capturar o intervalo de valores em um conjunto de dados e para identificar padrões de variação.
- Amplitude
A amplitude do intervalo de um conjunto é a medida mais simples de variabilidade e é calculado como a diferença entre os valores mais alto e mais baixo em um conjunto de dados. De acordo com Larson & Farber (2015, p. 79), para encontrar a amplitude, os dados devem ser quantitativos.
A amplitude é uma medida bruta de variabilidade, pois é sensível a outliers[1] e não leva em consideração a distribuição dos dados. No entanto, é útil para fornecer uma estimativa aproximada da dispersão de dados, principalmente ao lidar com pequenos conjuntos de dados.
- Intervalo Interquartil
O intervalo interquartil (IQR) é uma medida de variabilidade calculada como a diferença entre o terceiro quartil (Q3) e o primeiro quartil (Q1) de um conjunto de dados. O IQR representa os 50% intermediários dos dados e é menos sensível a valores discrepantes do que a amplitude do intervalo. É particularmente útil para identificar assimetria na distribuição de dados.
- Variância
A variância é uma medida de variabilidade que leva em conta a distribuição dos dados. É calculada como a média das diferenças quadradas de cada valor da média do conjunto de dados. A variância é uma medida útil de variabilidade, pois dá peso igual a todos os valores no conjunto de dados.
Para Castanheira (2012, p. 232), a variância nos permite comparar, simultaneamente, as médias de várias amostrar, desde que:
- Tais amostras tenham sido extraídas de populações que têm distribuição normal;
- As populações tenham o mesmo valor de variância;
- Tais amostras sejam aleatórias e independentes.
- Desvio Padrão
Calapez et all (1996, p. 138) definem o desvio padrão como uma medida de variabilidade comumente usada que é calculada como a raiz quadrada positiva da variância.
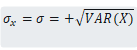
Onde X é uma variável aleatória. O desvio padrão representa o desvio médio de cada valor da média do conjunto de dados e é útil para descrever a dispersão dos dados em torno da média. O desvio padrão é mais interpretável do que a variância, pois está nas mesmas unidades dos dados originais.
- Coeficiente de Variação
O coeficiente de variação (CV) é uma medida de variabilidade usada para comparar a variação de conjuntos de dados com diferentes médias e unidades. É calculado como a razão entre o desvio padrão e a média do conjunto de dados, expresso como uma porcentagem.
Dado um par de variáveis X e Y, define-se coeficiente de correlação (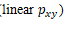 como
como
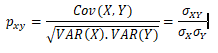
Verifica-se que .
Quando
, há correlação linear negativa perfeita entre X e Y
, a correlação linear é positiva e perfeita
, não há correlação linear entre X e Y.
2. Medidas Espaciais de Variabilidade
Medidas espaciais de variabilidade são comumente usadas na análise de dados geográficos para explorar a distribuição espacial dos dados, identificar padrões espaciais e avaliar a autocorrelação espacial.
- Autocorrelação Espacial
Para Dudé & Legros (2014, p. 75), a autocorrelação espacial é uma medida da similaridade de valores entre locais vizinhos em um conjunto de dados. É comumente usada na análise de dados geográficos para identificar a presença de padrões espaciais e avaliar o grau de agrupamento ou dispersão de dados. A autocorrelação espacial pode ser medida usando várias estatísticas, incluindo a estatística I de Moran e a estatística C de Geary.
Embora ambas as estatísticas meçam mais ou menos a mesma coisa, elas são baseadas em diferentes medidas de associação entre variáveis: a estatística I de Moran é baseada na medida de covariância, enquanto a estatística C de Geary é baseada na lacuna entre duas medidas da mesma variável (Dudé & Legros, 2014, 75).
I de Moran é uma medida global de autocorrelação espacial que varia de -1 a 1, onde um valor de 1 indica autocorrelação espacial positiva perfeita (isto é, valores semelhantes são agrupados juntos), um valor de -1 indica autocorrelação espacial negativa perfeita (isto é, valores diferentes são agrupados juntos) e um valor de 0 indica nenhuma autocorrelação espacial (ou seja, os valores são distribuídos aleatoriamente). O C de Geary é outra medida global de autocorrelação espacial que varia de 0 a 2, onde um valor de 1 indica nenhuma autocorrelação espacial, valores maiores que 1 indicam autocorrelação espacial negativa (ou seja, valores diferentes são agrupados) e valores menores que 1 indicam autocorrelação espacial positiva (ou seja, valores semelhantes são agrupados).
- Geoestatística
A geoestatística é uma abordagem estatística comumente usada na análise de dados geográficos para modelar a variabilidade espacial e fazer previsões em locais não amostrados. Baseia-se na suposição de que a variabilidade espacial pode ser decomposta em diferentes componentes.
Métodos geoestatísticos, como krigagem e cokrigagem, podem ser usados para estimar a estrutura de correlação espacial e fazer previsões em locais não amostrados.
Krigagem é um nome genérico adotado pelos geoestatísticos para um grupo de técnicas de estimação baseado em minimização da variância do erro […]. Este passo de análise (estimação) é absolutamente clássico, a despeito da confusão trazida pelo novo nome ‘Kriging’. A essência da geoestatística não reside na krigagem, mas sim em: documentar a decisão de estacionaridade, escolher certos dados (transformados ou não) a serem utilizados e inferir modelos de covariância (Journel apud Ribeiro Jr., 1995, p. 30).
Kriging é um método de interpolação linear que estima os valores em locais não amostrados com base na estrutura de correlação espacial do conjunto de dados. A cokrigagem é uma extensão multivariada da krigagem que usa variáveis auxiliares para melhorar a precisão da previsão.
3. Aplicações de Medidas de Variabilidade na Geografia
Na geografia, as medições de variabilidade são usadas para entender a extensão da variabilidade ou disseminação de um determinado fenômeno ou característica geográfica.
Segundo Da Silva (2016), uma das aplicações significativas de medidas de variabilidade na geografia é na análise de dados climáticos. Os dados climáticos são medições das diferentes condições meteorológicas registradas durante um período prolongado, como temperatura, precipitação, velocidade do vento, umidade, entre outras. Esses dados geralmente são registrados em diferentes estações meteorológicas em uma região ou país.
Outra aplicação de medidas de variabilidade na geografia é na análise de dados econômicos. Dados econômicos são medidas de diferentes indicadores econômicos, como produto interno bruto (PIB), taxa de inflação, taxa de desemprego e taxa de pobreza, entre outros. Esses dados geralmente são registrados em diferentes níveis administrativos, como país, estado ou província.
Medidas de variabilidade também são usadas na análise de dados espaciais em geografia. Os dados espaciais são medidas de características geográficas, como elevação, uso da terra e densidade populacional, entre outros.
Considerações Finais
Em conclusão, as medidas de variabilidade são importantes ferramentas estatísticas que nos permitem quantificar o grau de dispersão ou espalhamento dos dados. Na análise de dados geográficos, as medidas espaciais de variabilidade são particularmente úteis porque levam em conta a estrutura espacial dos dados e nos permitem explorar a distribuição espacial dos dados, identificar padrões espaciais e fazer previsões em locais não amostrados.
Em conclusão, as medidas de variabilidade são ferramentas estatísticas essenciais usadas na geografia para entender a extensão da variabilidade ou propagação de um determinado fenômeno ou característica geográfica. Eles são particularmente úteis na análise de dados climáticos, dados econômicos e dados espaciais. Os insights fornecidos por essas medidas podem ajudar formuladores de políticas e pesquisadores a tomar decisões informadas sobre alocação de recursos, desenvolvimento de infraestrutura e gestão ambiental, entre outros.
Bibliografia
Calapez, T. et all. (1996). Estatística Aplicada. Lisboa: Edições Sílabo.
Castanheira, N. P. (2012). Estatística Aplicada a Todos os Níveis. 5ª ed., Curitiba: Ibpex.
Da Silva, J. (2016). Segredos da Estatística para Geografia. Florianópolis: Cadernos Geográficos.
Dudé, J. & Legros, D. (2014). Spatial Autocorrelation. New York: John Wiley & Sons, Inc.
Larson. R. & Farber, B. (2015). Estatística Aplicada. 6ª ed., São Paulo: Pearson Universidades.
Ribeiro Jr. (1995). Métodos Geoestatísticos no Estudo da Variabilidade Espacial de Parâmetros do Solo. São Paulo: Piracicaba.
- Consultas na internet
Britannica. (2023). Range – Statistics. Acessado em 20.03.2023. Fonte: https://www.britannica.com/topic/range-statistics
Universidade Federal do Rio Grande do Sul (UFRGS). (2023). Identificando e tratando Outliers. Acessado em 22.03.2023. Fonte: https://www.ufrgs.br/wiki-r/index.php?title=Identificando_e_tratando_Outliers
[1] Outliers, na estatística, são observações que apresentam grande afastamento da maioria dos dados de uma série.